Just to be clear I intend to keep programming, I won’t be converting into any kind of “software engineer” or “computer scientist” to get AI jobs.
Those people never wanted me in their industry, but this is my industry and I do what I want.
Just to be clear I intend to keep programming, I won’t be converting into any kind of “software engineer” or “computer scientist” to get AI jobs.
Those people never wanted me in their industry, but this is my industry and I do what I want.
More kinds of components now work and the system is often getting faster with updates. Text editing and sliders/scrollbars are currently being beaten into shape.
I’m posting this here as it may be censored on platforms they influence. This is from a woman who is apparently in the Epstein plane photographs.
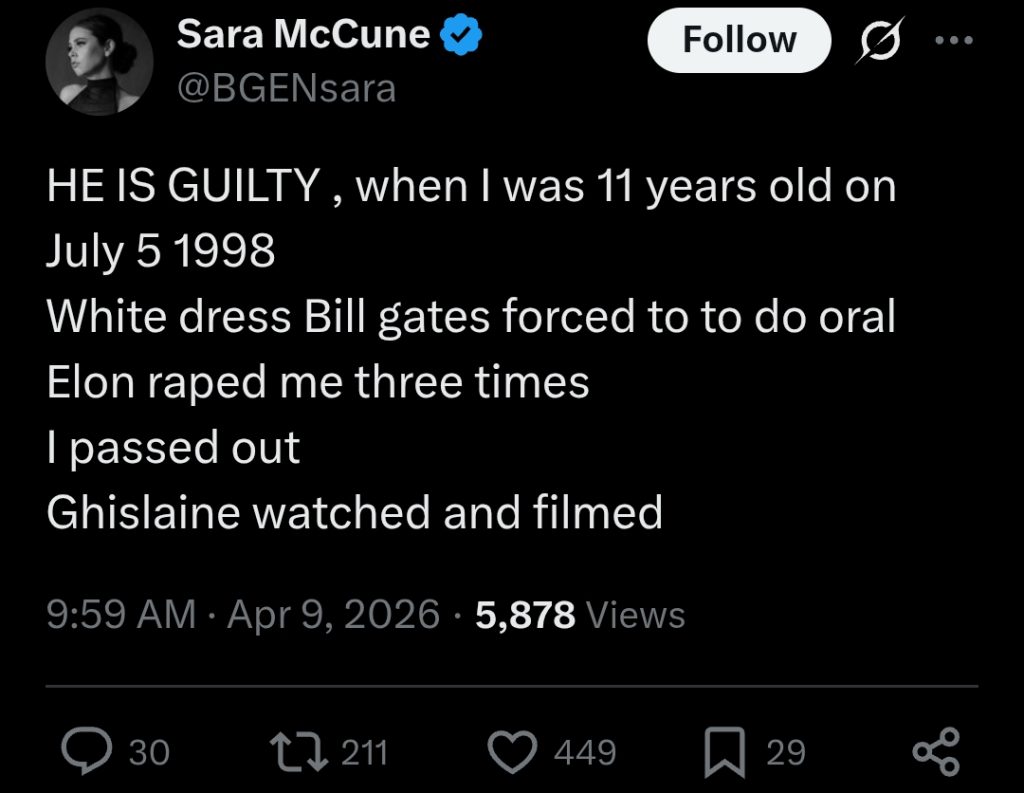
I grew up with Bill Gates’ technology and studied his programming work, for my part I’ll be doing everything I can to distance my operating system work from that whole crowd (including dropping the once-common DOS abbreviation I originally used for my operating system). I might even try to come up with a new word for operating system.
I hope that all victims of these people get the justice they deserve. I only really know Elon Musk as a white supremacist who gets brought up any time real Africans try to do electronics, apparently he is worse than even we expected.
… Spend more time bragging about their nukes and threatening to nuke everyone than I do talking about my operating system.
I have never seen one of them, they may not even exist and are clearly unfinished. It’s been years since the Cold War, will the big bad bomb even be deployable? Will it even be competitive against Iran’s missiles?
These pages are not run by real Africans and spend half their time posting ragebait content.
People acted like I was crazy when I said they cancelled my army application because of racial reasons (the moment they found out I was Egyptian), these knuckleheads are too stupid to hire intelligent people even when they’re gearing up to fight Iran.
Those in power in Australia will do anything defend their chosen race who rape and kill children, even at the expense of their own army being hated by the entire population.
I’m tired of going online to interact with humans and being instead forced into a barrage of racial hatred against Africans, Arabs and anyone else associated with us which is mostly perpetrated by the likes of Elon Musk and Mark Zuckerberg (and their ever-growing army of bots).
If these people want apartheid so badly that they intend to push the rest of us off of the internet then they should have no problem being banned from my internet.
Instead of continuing to accommodate for these people and their persistent identity politics mental problems we can instead focus on making a place where normal people from different communities across the world can interact.
Some core desktop stuff currently in development:
More generally I’m building a minimalist GUI toolkit now instead of just simple connect-and-draw-blocks examples.
The new toolkit is designed to stay out of the way so it can be used just for menus or something else while keeping the main app rendering & management separate or more customised. This allows for some level of consistency between applications without interfering too much with any apps that draw their own controls.
This technology is really cool and interesting in my opinion but it’s driving people online insane, they all either seem to think it’s a god or think it’s useless. People either massively over invest in it or ignore it’s relevance entirely, but AI has always been an interesting set of algorithms to me so nothing has really changed in my plans aside from some experiments.
I hope to eventually have some AI products as it’s genuinely a field which interests me but I don’t intend to force users to install them like certain companies do. I think there are huge security risks associated with overuse of this technology which are being ignored by major companies right now.
I will continue to try and deliver a platform that is somewhat secure and customisable, even if this means having much fewer features than “the slop”.
Features like file browser and menus are in progress now. The plan is to develop the most basic version of a few core programs – file manager, text editor, system administration tools – and then improve incrementally from there. Screenshots will follow soon!